
SNR-Aware low light enhancement
Github:
Intro
해당 모델에서는 낮은 SNR값을 가지고 있는 부분은 정보량이 부족하고, 높은 SNR값을 가지고 있는 부분은 local information이 충분하다고 가정하고 spatial-varying enhancement 를 수행하는 것을 목표로 합니다.

높은 SNR을 가지고 있는 region의 경우 Residual Conv block 로 local feature를 추출하고, 낮은 SNR을 가지고있는 region은 Transformer로 non-local(global) feature 를 추출하게 됩니다.
논문에서는 SNR Map 이라는 것을 생성하여 아래의 과정에 적용하는데, 이것이 위의 Spatial-varying enhancement를 구현하는 핵심 요소라고 할 수 있습니다.
- 새로운 self attention method를 통한 SNR-aware transformer
- SNR-guided Feature fusion
Model structure
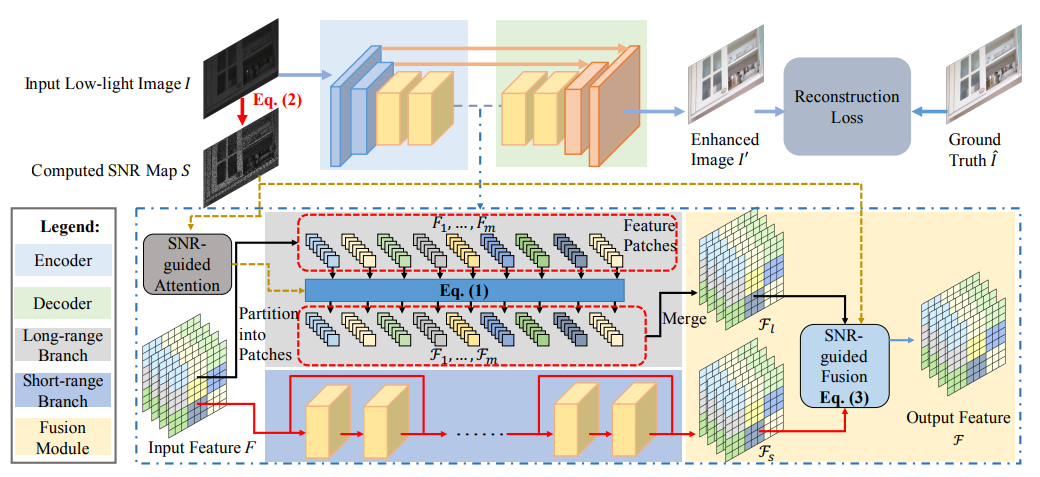
모델의 구성은 크게 5가지로 나눌 수 있습니다.
-
SNR Map
Input image만을 사용해 SNR map을 만듭니다.
-
Encoder and Decoder
Residual Conv block으로 구성되어있고, Encoder, Decoder 간의 Skip connection이 존재합니다.
-
Long range branch
Transformer로 구성되어 있으며, high noise region을 attention 하는것을 피하기 위해서 SNR map을 참고하는 SNR-guided self attention을 수행합니다.
-
Short range branch
Residual Conv Block을 구성되어있습니다.
-
Fusion module
SNR map을 참고하여 High SNR region은 Short range, Low SNR region은 Long range의 Feature map에서 feature를 가져와 fusion 합니다.
Details
Encoder-decoder, short range branch 부분은 논문에 나와있지 않아 코드를 보고 작성한 내용이라 정확하지 않을 수 있습니다.
SNR map
SNR map
Noise map 는 Input image를 gray scale로 변환해 생성합니다. (0.299 * *R + 0.587 ** G + 0.114 * B)
-
생성
코드에서는 denoised grayscale input 를 만들 때 사용하는 함수로 5x5 Average Blurring을 사용하였습니다. (ablation study에서 Average blurring 대신 non-local blurring, BM3D로도 실험하였는데 대부분 비슷함.)
-
Noise map
위에서 만든 estimated denoised map 와 gray scale input 의 차이를 구합니다.
-
SNR map
코드에서는 으로 SNR map 를 정의하였습니다.
저자는 이 방법으로 만든 SNR map 이 정확하진 않지만 대충 유효한 결과를 만들어낸다고 합니다.
Encoder
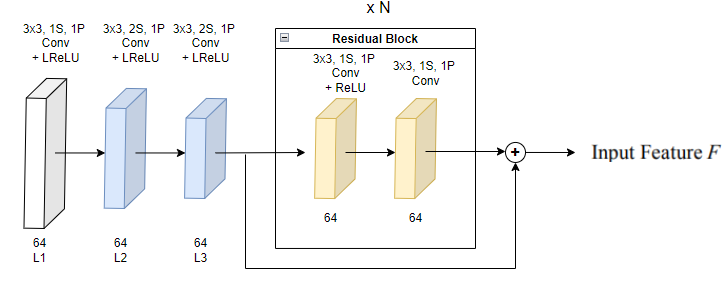
코드에서는 Encoder의 Conv layer들은 64채널 고정, Residual Block은 1개만 사용하였습니다.
Long range branch
Feature patches
,
Long range branch에서는 우선 Encoder를 통해 나온 Input feature 를 개의 patch로 나누는 작업을 합니다.
height = fea.shape[2]
width = fea.shape[3]
fea_unfold = F.unfold(fea, kernel_size=4, dilation=1, stride=4, padding=0)
fea_unfold = fea_unfold.permute(0, 2, 1)코드에서는 patch size = 4 로 되어있으며, Input feature를 unfold(kernel=4, dilation=1, padding=0, stride=4) 를 통해 에서 형태로 변환 후 Multi head self attention(MSA) 을 수행합니다.
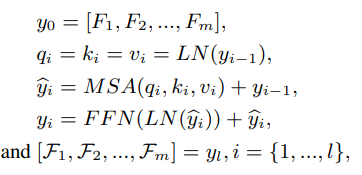
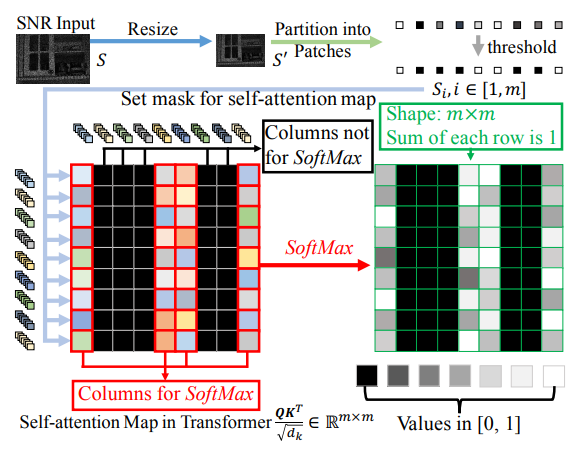
이 때, 일반적인 self attention을 진행하게 되면, 모든 feature patch에 대해서 global 하게 attention을 하게 됩니다.
따라서 저자는 High noise region에 대해서 attention하는것을 피하기 위해, 앞서 구했던 SNR map을 self attention의 mask로 사용하는 방법을 제시합니다.
mask_unfold = F.unfold(mask, kernel_size=4, dilation=1, stride=4, padding=0)
mask_unfold = mask_unfold.permute(0, 2, 1)
mask_unfold = torch.mean(mask_unfold, dim=2).unsqueeze(dim=-2)
mask_unfold[mask_unfold <= 0.5] = 0.0SNR map 를 mask로 사용하기 위해 , Input feature 의 사이즈로 resize하여 을 얻습니다.
를 feature patch 으로 나눌때와 마찬가지로, 를 unfold 하여 → → 형태로 만들어줍니다.
그 후 threshold(0.5)를 걸어 최종적으로 self attention mask를 얻어냅니다.
이와 같은 과정으로 모델의 핵심요소인 SNR-guided transformer 를 수행하여, High SNR region에 대해서 noise가 적은 region에 대해서만 global한 attention 결과 Long range feature 를 얻게 됩니다.
Short range branch
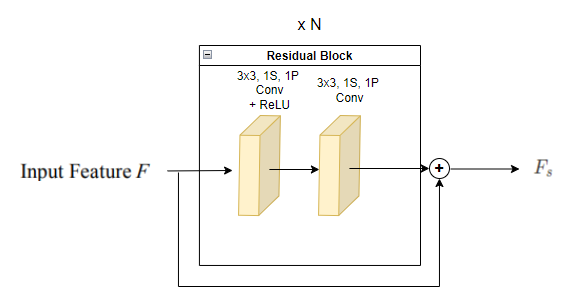
Short range branch에서는 앞서 Encoder-decoder에서 사용된 것과 동일한 Residual Convolution Block을 N개 통과하는 구조입니다. (코드에서는 6개)
이를 통해 Short range feature 를 얻게 됩니다.
Feature fusion
Feature fusion
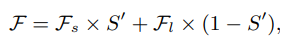
Feature fusion equation
SNR map 를 long, short branch Feature map 의 size 로 resize하여 을 얻습니다.
그 후 [0,1] 로 normalize 하고 에 interpolate weight로 곱하여 Output feature 를 얻습니다.
이를 통해 High SNR region은 Conv 를 통과한 local feature, Low SNR region은 Transformer를 통과한 global feature를 취하여 Spatially-varying Feature Fusion을 수행하게 됩니다.
Decoder
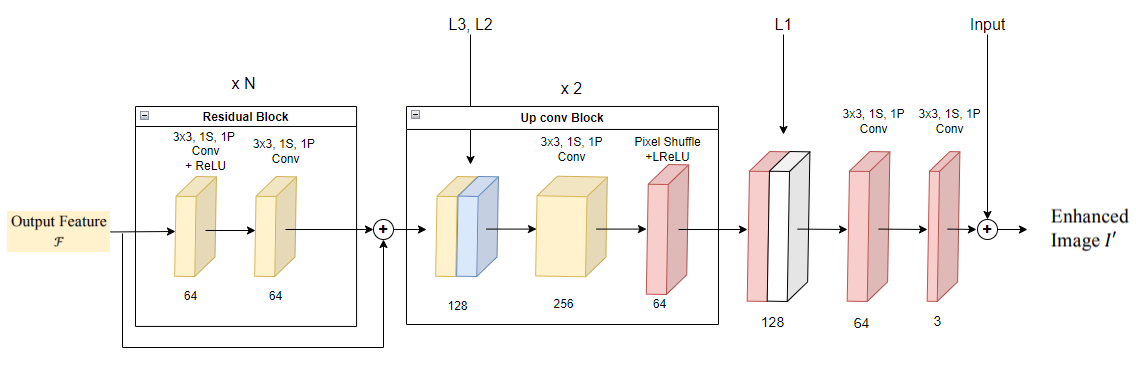
Decoder에서는 Feature Fusion을 통해 얻어진 Output Feature 를 input으로 받아 Residual Conv Block을 통과합니다. 코드에서는 마찬가지로 1개만 사용하였습니다.
그 후 Encoder의 L1~L3 feature map과 skip connection, conv, pixel shuffle를 수행하는 Up conv block을 통과하고 최종적으로 Input과 더하여 Enhanced Image 을 얻습니다.
Loss
= Charbonnier loss
= Perceptual L1 loss (vgg19)
= Hyper parameter (0.04)
Experiments
다음과 같은 framework에 대해서 Ablation study를 진행하였습니다.
- “Ours w/o L” removes the long-range branch, so the framework has only convolutional operations.
- “Ours w/o S” removes the short-range branch, keeping the full long-range branch and SNR-guided attention.
- “Ours w/o SA” further removes the SNR-guided attention from “Ours w/o S”, keeping only the basic transformer structure in the deepest layer.
- “Ours w/o A” removes the SNR-guided attention.
